By Mihaela Krznar on 18 June 2026
Textile catalogs are some of the hardest things in commerce to search with words. A stripe that’s 2mm wider, a floral motif shifted slightly off-center, the same weave in twelve colorways – these are differences a buyer can spot instantly but oftentimes can’t type into a search box. “Green plaid cotton” returns hundreds of near-misses and the right match might not even be one of them.
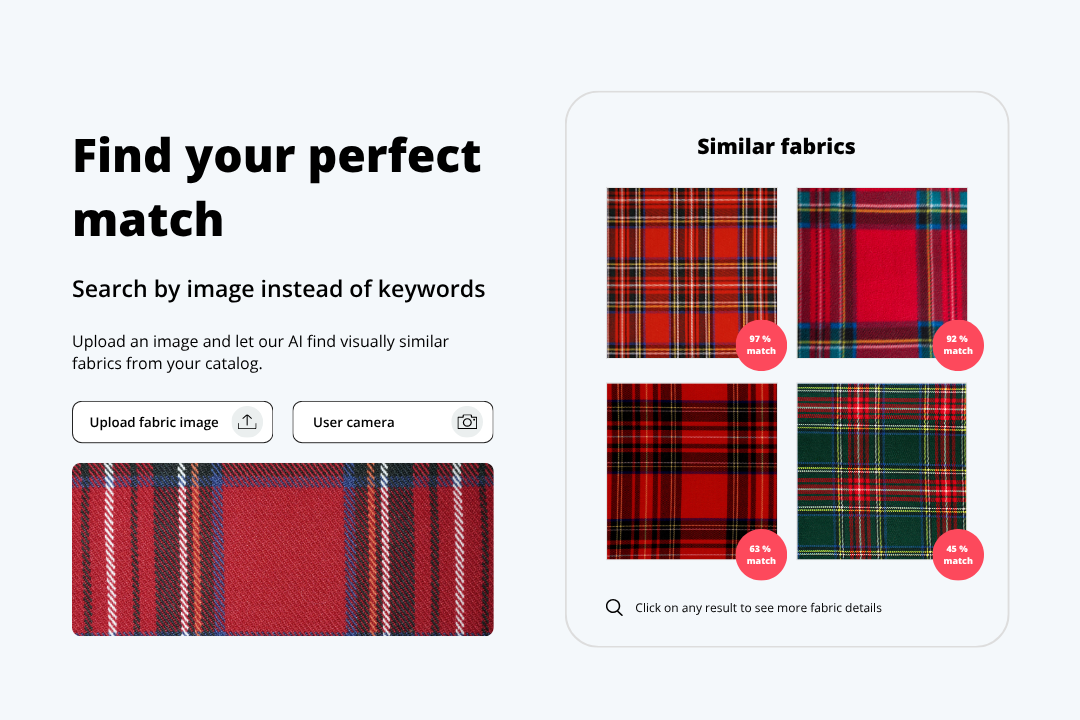
Visual search solves this by changing the query itself: instead of describing a fabric, the user can simply upload a photo of it and the system returns the closest visual matches from the catalog. For manufacturers, wholesalers, textile software providers and design teams managing large pattern libraries – that shift from describing to showing – removes the single biggest source of search friction in the catalog.
Most visual search content talks about this in terms of fashion shoppers browsing a storefront. The textile industry’s version of the problem is more structural. A B2B fabric catalog isn’t organized the way a clothing catalog is – patterns repeat across product lines under different names, the same design ships in multiple weights and finishes, and “stripe” or “floral” as search tags collapse hundreds of visually distinct options into a handful of buckets that don’t actually help anyone find what they need.
That’s a tagging and information-retrieval problem before it’s a fashion problem, and it shows up in three places specifically:
Sourcing and procurement. A buyer has a swatch, a reference photo, or a competitor’s product shot, and needs to know whether something close to it already exists in inventory or a supplier’s catalog – without paging through folders by hand.
Sampling and production matching. Manufacturing teams need to match a sample against thousands of existing SKUs to avoid commissioning a near-duplicate or to confirm a production reference matches spec.
Custom and design work. Tailors, interior designers, and architects routinely work from inspiration images – a photo of a couch, a swatch from a client – and need the closest available match, not a keyword guess.
A visual search system converts each catalog image into a numerical representation (a vector) that encodes its visual features – pattern, color, texture, structure. When someone uploads a query image, it’s converted the same way, and the system returns the catalog items whose vectors are closest to it. For the full mechanics of how that conversion and matching process works, see our guide to visual search.
What’s specific to textiles is the fine-tuning step. A general-purpose visual search model trained on furniture or electronics doesn’t know that a 2mm stripe-width difference matters, or that a particular weave structure is more relevant than overall color when a sourcing team is looking for a match. That context comes from training the model on your own catalog images, which is why a generic, off-the-shelf visual search API tends to underperform on fabric-specific queries compared to one tuned on textile data.
Our visual search model is already pre-trained and built, but it becomes truly powerful for your use case when fine-tuned on your data. Because of that, it understands what visual similarity means in your specific business context based on the images you provide us with.
It is a highly scalable solution, so it doesn’t matter if you’re having 5000 images or 10 million, the performance remains fast and accurate.
Because the model is already built, onboarding is quick. We can fine-tune it on your dataset in just a couple of days and deliver a customized solution to your use case within weeks.

Example of a textile catalog
No, and this is worth being precise about, because the two get confused often. A fabric identification app (the kind built for consumers or QA teams) tells you what a fabric is made of – fiber content, weave type, care properties – usually from a close-up photo, sometimes with a microscope attachment for higher accuracy. Visual search doesn’t tell you what a fabric is made of; it tells you what’s visually similar to it in a specific catalog. You’d use a fabric identifier to answer “is this cotton or a cotton-poly blend?” You’d use visual search to answer “do we already have something like this in our catalog, or who supplies something like it?”
It’s also distinct from our fabric pattern detection API (which we cover in detail in our piece on AI fabric pattern detection). Pattern detection classifies an image into a category – floral, plaid, zigzag, etc – for tagging and filtering. Visual search doesn’t classify; it ranks the entire catalog by similarity to a specific reference image. In practice, the two work well together: pattern tags narrow the field, and visual search finds the closest match within it.
Velebit AI’s Visual Search can be integrated for both external users (customers) and internal users (teams, suppliers, partners). Here are some common use cases:
The model starts pre-trained on general visual similarity, then gets fine-tuned on your catalog images so it learns what “similar” means for your specific products and structure. The process in practice:
It’s a search solution where a user uploads a photo of a fabric or design instead of typing a description and an AI model returns the most visually similar items from a textile catalog, useful when patterns are too subtle or too similar to describe accurately in words.
Visual search finds visually similar items within a specific catalog. A fabric identification app determines what a fabric is made of (fiber content, weave, care properties). They answer different questions and aren’t substitutes for each other.
Fabric pattern detection API classifies an image into a fixed category (floral, plaid, stripe, etc) for tagging and filtering. Visual search ranks an entire catalog by similarity to a reference image rather than sorting it into categories. They’re often used together.
Yes. Labeled data improves accuracy, but fine-tuning can start from whatever stage your data is in – a demo on your own catalog will show actual performance before any commitment.
As a REST JSON API, either as a cloud SaaS or on-premise where data privacy requirements call for it. It’s designed to integrate with existing search infrastructure (Elasticsearch, Solr) rather than replace it outright.
The only way to know whether this fits your catalog’s specific patterns, structure and edge cases is to test it on your own data.
Explore the product or get in touch and we’ll set up a demo using your dataset.
Partner with us to develop an AI solution specifically tailored to your business.
Contact us



