By Admin on 12 March 2020
Whether you’re a marketplace, a classifieds, or an e-commerce site, items you are selling are categorized into categories to enable buyers to find what they seek more easily. And who is categorizing them? People who are posting the ads.
In the case of a marketplace, these are sellers, professionals, or non-professionals, trying to sell their possessions or services. In the case of an e-commerce site, these are the employees in charge of the inventory.
Non-professionals don’t sell a lot of things and are not familiar with the categorization hierarchy. They may lose a lot of time to find the right category, and that may frustrate them. They want to post their ad as fast and efficiently as possible and sell the stuff they are selling. Classifieds sites or e-commerce sites can have thousands of categories. Some larger, like eBay, have even more than 10,000.
Professionals, on the other hand, sell a lot of stuff and post even more. They are familiar with the category hierarchy, but they spend a lot of time clicking and selecting the categories because there are a lot of items. Even a small improvement in ad posting can save them a lot of time.
In today’s world, abundant with information, it’s hard to sell anything without images. Even videos are expected in ads. There are categories like services, where it’s hard to find relevant and informal photos, and they make less sense. But for the majority of others, images started to be a necessity.
Machine learning, a branch of the area of Artificial Intelligence, is getting more and more powerful and can be used to build a system that predicts categories based on images. If the ad posting process is designed to select or take pictures as a first step, a lot can be inferred from them. Predicted categories can be suggested to the user as a shortcut in navigating through the hierarchy.
Besides categories, machine learning can be used to generate an ad (or item) title. This can reduce the time needed to post an ad, but the ads may look dull and “robotic”. People often prefer their own “touch” when creating ads. If written imaginatively, ad title can significantly help to sell faster.
Title suggestion can be implemented more easily if the category hierarchy is rich and deep. If a marketplace has a category Cellphones -> iPhone -> iPhone 11, it is easy to predict the title like iPhone 11 cellphone. For more broad categories, machine learning can be used to generate the title from an image.
If title suggestion is not used and the user must write it, the title itself can be used to predict and suggest categories. Machine learning models that use text and images separately can be merged to create a system that uses text and/or images to predict categories.
Velebit AI has built such a system. It consists of two convolutional neural networks, one for images and other for text, merged. These neural networks predict leaf categories. Then, a proprietary post-processing algorithm is used to predict the final set of K (most of the time, K=3 or 5) categories (not only the leaf ones). This algorithm has to know the whole hierarchy structure of categories, to be able to optimize the resulting categories.
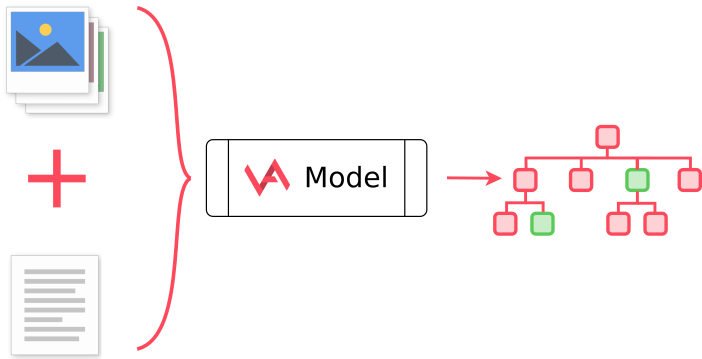
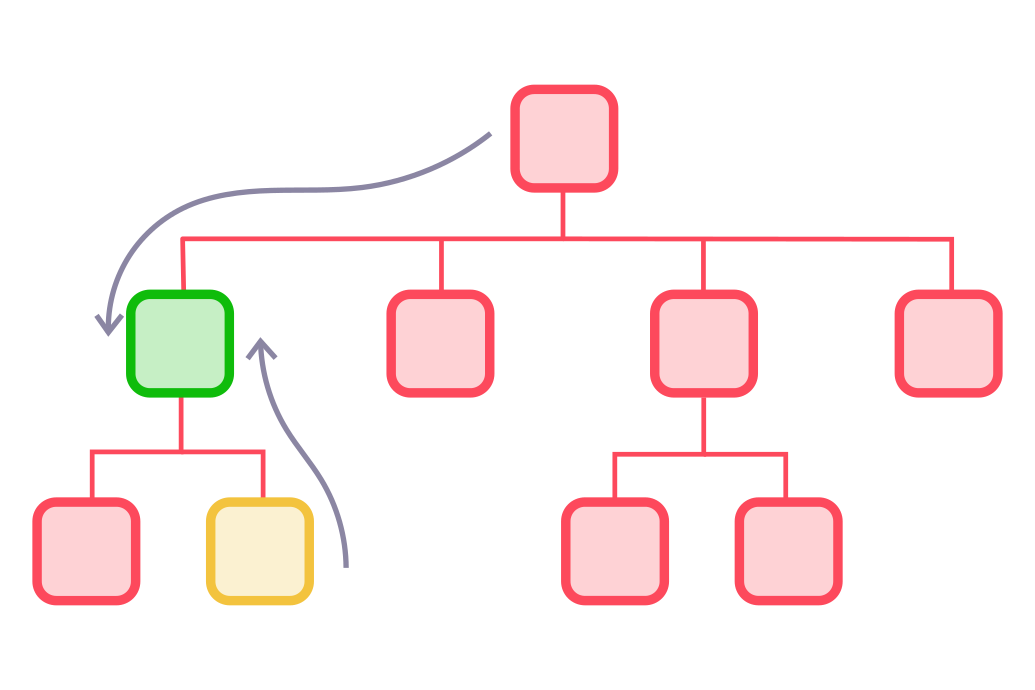
This algorithm minimizes the number of steps the user needs to take to reach the desired leaf category. Sometimes it may choose to return leaf categories:
But then, if the model has failed in prediction and the right category is Samsung Galaxy, the user must do a lot of clicks to navigate from iPhone 11 to Samsung Galaxy. In this case, the algorithm may conclude it is better to offer the following categories:
This way, the user only has to navigate from Samsung Galaxy to Galaxy S8 category (1 step). In this example, the suggestion is less specific but more accurate. The post-processing algorithm is doing exactly that: based on the machine learning model confidences, it is modifying the node suggestions to reduce the expected number of steps the user has to take.
Of course, if the model is very certain in a particular answer, it may return only one node, for instance:
This system lowers the number of choices for users and speeds up the process.
Our category prediction system is deployed on a number of sites. On one of them, the average distance from predicted to the correct leaf is only 0.4 user clicks on average. This system has shortened the average time to post an ad from 96 seconds to only 32 seconds.
Google, Amazon, Facebook, and other large companies have spoiled us too much with their smart suggestions, tips, and corrections. You can often hear that those systems are “reading our minds”, meaning their suggestion accuracy is quite high. When you add the younger generations to the bunch, which expect everything to be instant and fast, you end up with users that have high expectations of suggestion services.
There are a lot of off-the-shelf solutions for image tagging/categorization that seem like a good solution for category prediction. There are Google Cloud Vision API, Amazon Rekognition, Microsoft Azure ML, IBM Watson, and many others. Let’s see what they return for a given image of an iPhone 6s device.

Results of using existing computer vision APIs:
| Velebit AI | – Cell Phone – Apple iPhone – iPhone 6s |
| Amazon Rekognition | – electronics – iPod – cell phone – computer – mobile phone … |
| Microsoft Azure ML | a close up of a device |
| IBM Watson | – stereo system – audio system – video iPod – cigarette case – figure – jade green color |
| Google Vision API | – mobile phone – gadget – electronic device – feature phone – communication device – product |
Although you can’t say that the returned tags and categories are wrong, they don’t offer much value to the client that has their own categories of items. How will one map these tags to categories? This problem of mapping to categories is almost as hard as to build an image categorization model that returns categories based on an image.
Velebit AI offers a different approach. We have a general model that gets fine-tuned on a custom category hierarchy. This way, we can always return relevant nodes, and the post-processing algorithm mentioned above optimizes the results to reduce the number of clicks and save time.
With no upfront costs, you send us the CSV export of your data, and in one week, we expose you the API endpoints you can test. If you are satisfied and you decide to use it, you start paying a subscription fee based on the number of requests per day.
Contact Us or follow Velebit AI on LinkedIn.
Partner with us to develop an AI solution specifically tailored to your business.
Contact us