
By Bartol Freskura on November 26, 2019
According to Wikipedia:
Optical character recognition or optical character reader (OCR) is the electronic or mechanical conversion of images of typed, handwritten or printed text into machine-encoded text, whether from a scanned document, a photo of a document, a scene-photo (for example the text on signs and billboards in a landscape photo) or from subtitle text superimposed on an image (for example from a television broadcast).
Thank you, Wiki, a bit too descriptive, but very accurate. Here’s an image demonstrating OCR in action just in case the definition was too much for you.

OCR is a widely used technology even today when digital almost always comes in front of analog. Number plates, business cards info, old books, and traffic signs are just some examples where digital is still not feasible (although digital plates would be really cool) and in such cases, OCR comes into play. Despite being long in existence, OCR is far from perfect because real world text can get pretty complex.
Why would you want to do this? Ask people from companies that put their products on shelves and they will immediately tell you: “We want to know how we fare price-wise against the competition”. It may not seem obvious, but it is pretty hard to find real store prices. Not all stores have online shops and even when they do, prices can vary significantly in each store, especially in stores geographically well apart. This is why companies pay big bucks for sales representatives who will visit stores and manually write down actual prices. It’s a demanding and error-prone job which has to be done at least once per month.
It would help if they could just take a picture of the shelf, and the magic would fill in all the product prices. Fortunately for them, the magic exists and it comes in a form of deep learning and OCR.

The idea is to capture an image of a shelf as the one above, crop out price tags, read prices, and finally connect prices with adequate product types. This blog will focus on the price reading part.
You know that feeling when you think something is easy but then as you dive deeper into the subject, numerous complications pop out of nowhere? Well, reading price tags is like that. Price tags are usually computer generated and have some structure so it seems that OCR algorithms would read them without a problem. Our tests showed us otherwise. We tried the obvious two solutions when it comes to OCR - Tesseract and Google OCR API. Furthermore, we tested a model optimized for the Street View House Numbers dataset, coming from a paper published by Google.
Tesseract is an open sourced library that uses an OCR engine libtesseract and a command line program tesseract to recognize character patterns. It is maintained by Google which implies it is frequently updated and is well documented. Since the v4, they’ve added a deep neural net (LSTM) based OCR engine which is focused on line recognition, but also still supports the legacy Tesseract v3 which works by recognizing character patterns.
We won’t focus on explaining all features Tesseract offers but will only try to read price tags with a touch of options tweaking. The command and parameters used were:
tesseract --oem 1 -l hrv --psm 11 <image_path> out
--oem – specifies OCR engine. 1 is for LSTM (v4), 0 is for legacy and 2 is a combination of two. We want to utilize the neural network only so we use 1.
--l hrv – Language flag. Uses specialized model designed for the specified language. Here we used the Croatian language files. Take a look here to see how to install arbitrary language files. Files for English come with the installation.
--psm 11 – Page segmentation mode. We want to find as much text as possible so we use option 11.
out – is the name of the file where the read text will be saved. Extension .txt is automatically appended.
First, we analyze full price tag images where the price and product description are listed. Price tags are cropped from a larger image and the product description text is very small and blurry so we don’t expect to read it. Nevertheless, the price is still visible and the OCR engine should manage to read it.

Pretty bad if you ask me. Now, Tesseract mentions some tweaks that could help with accuracy and we tried these tweaks to no avail, but the biggest issue is mentioned in this sentence:
By default, Tesseract is optimized to recognize sentences of words. If you’re trying to recognize something else, like receipts, price lists, or codes, there are a few things you can do to improve the accuracy of your results, as well as double-checking that the appropriate segmentation method is selected.
It seems Tesseract just wasn’t built for reading prices from price tags. Next, we tried giving it accurately cropped prices but the results were still problematic.

Tesseract offers custom training which we didn’t try because it needs a lot of annotated data. This could help because neural networks perform much better when trained on specific datasets such as price tag images.
Google OCR is part of the Vision services Google offers. The main advantage of this service is the ease of use and state-of-the-art algorithms Google uses. Here you can upload arbitrary images to see the service in action. We’ll use this page to make tests on our price tags.
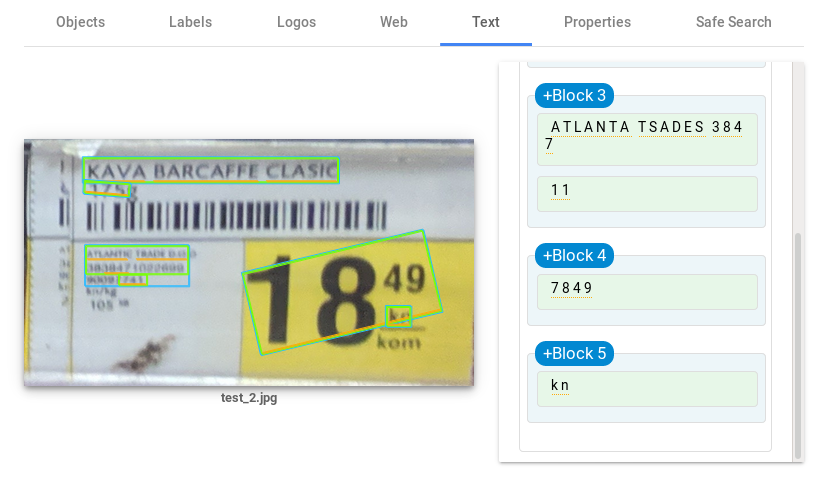
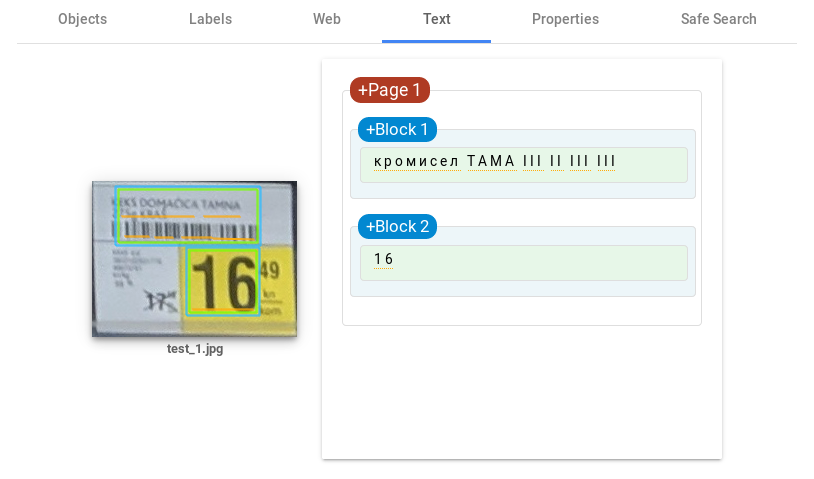
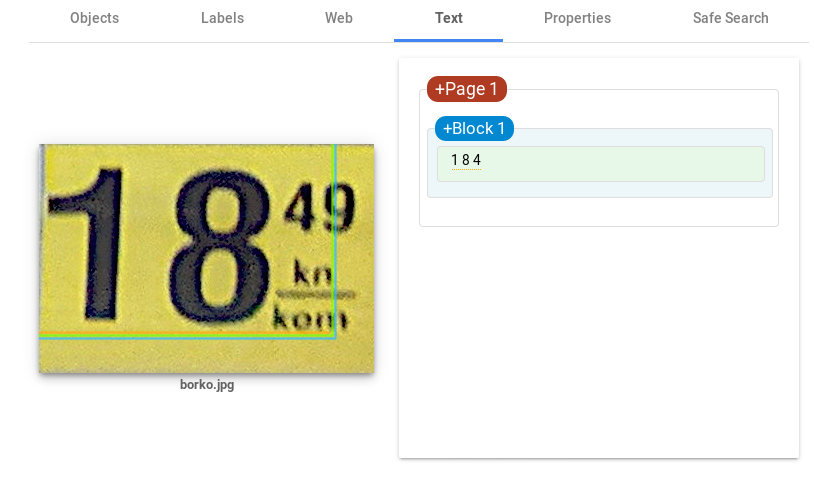
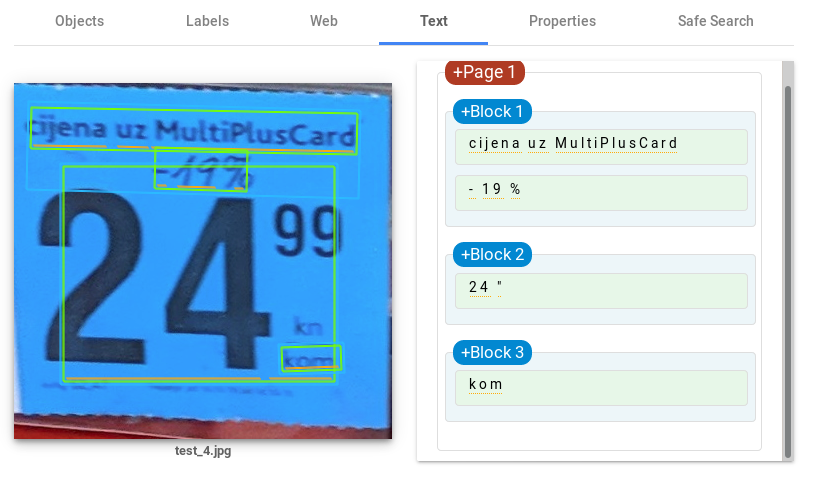
Leaps and bounds better than Tesseract! The main advantage comes from detecting blocks of text which simplifies the image structure and enables cleaner text recognition. Although much of the text was successfully read, issues with prices still remain. Even when the text is isolated the results are not perfect.
The biggest downside of Google Vision API is the pricing. The price is calculated with respect to the number of total units (images) processed. Depending on the number of units and the frequency of calling the API, the cost can end up quite high.
Sounds complicated? Yes, but the idea from the paper is quite simple, but an effective one. The idea is to use a Deep Convolutional Neural Network to read house numbers captured by Google’s Street View cars. The neural network has five outputs and each output tries to recognize one digit. If the number has less than five digits, the network predicts empty placeholder values for places where the digit doesn’t exist. The number of outputs is limited to five because almost all house numbers have at most five digits. While this is not a full OCR solution that can read any text, it is a perfect solution we need for price reading because prices on price tags are also limited to a certain number of digits and usually have some kind of structure.
This Github repo contains code that reproduces results from the paper in the Pytorch library. The interesting part came when we gave the model trained on SVHN images price tag images.

On both full price tag and cropped price tag images, the model found correct values before the decimal separator. The values after the decimal separator were probably not found because the model was not trained on images where all digits are not of the same size and are not aligned.
We fixed this by fine-tuning and customizing the existing model on our sample dataset. The customized model had two heads with each head consisting of two softmax activation outputs, first head for the values before, and the second one for the values after the decimal separator.
It is obvious that we haven’t done a full blown analysis on an adequate sample of images, but despite that, our results show OCR technology is still far from perfect. General OCR engines still don’t go toe to toe with engines trained on custom datasets, even when the input image text is clearly visible.
Reading prices is just one use case among many and the above analysis may not hold for some other use case. Among open source, paid and custom solutions, it is up to you to choose the most suitable approach for your use case.
Technical and business lessons from real AI projects
Partner with us to develop an AI solution specifically tailored to your business.
Contact us