- Services
-
Products
- Automatic Tagging
- Search & Discovery
- Content Moderation
- Case studies
- Company
- Blog
- Pricing
- Let's talk
Case Study
Company |
Industry |
 |
E-commerce |

KupujemProdajem is Serbia’s largest online classifieds platform, founded in 2008. With over 3 million users and more than 6 million active listings, it covers everything from cars and electronics to real estate, jobs and services. Known for its scale, it’s become the go-to place for buying and selling in Serbia. The platform plays a central role in the region’s e-commerce ecosystem.

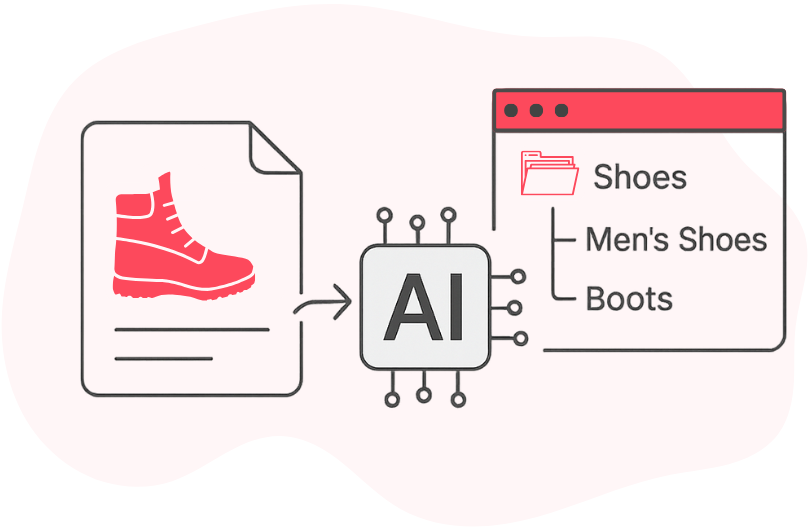
Good category suggestions shorten the time required for users to post the items on the KupujemProdajem platform. Up to 5 categories is always suggested. If, in these 5 categories, there is no correct item, the user may choose one of these because navigation through the whole category tree can last a long time.
What changed?

With over 6 million active listings spread across 1,600+ categories, categorization at scale becomes a challenge. Like most classifieds platforms, KupujemProdajem deals with a long-tail distribution: while some categories hold hundreds of thousands of items, many others have fewer than 50, making accurate classification quite tricky.
This project focused on improving the experience for sellers listing items on the platform. Each user has to navigate through 1600 categories to find the one where the item should be placed.
Manually placing an item was slow and error-prone, so KupujemProdajem developed a prediction model that suggested the most relevant category based on item titles.
The goal of this project was to improve the existing model by building a text-based machine learning classification model trained on their data to improve accuracy and user experience.

The training data consisted of items and their categories (selected by users). While most of these labels were accurate, some were off — especially in certain categories. This didn’t impact training as much, but it did make evaluation tricky. In categories where even 10% of the labels were incorrect, reaching high accuracy (above 90%) was nearly impossible, since the model was being judged against inconsistent ground truth.
It is impossible to properly train a large text classification model on 10-20 items per category, especially when some categories contain 200k+ items.
Contains a large variety of items that sometimes should be in another category
Some item titles, like those for books, are too vague on their own. Without additional context, it’s often impossible to tell what genre a book belongs to just from the title.

We fine-tuned a multilingual text classification RoBERTa-based model to the KupujemProdajem dataset for item categorization. We’ve chosen a multilingual model to achieve better performance for the Serbian language because all titles are written in Serbian. The resulting model achieved better accuracy than the model previously used.
For the categories with less than 100 examples, we used a large language model (LLM) to augment the dataset with more examples. This data augmentation helped boost both individual category accuracy and overall model performance.
We exported the optimized model in a format that runs efficiently on a standard CPU. To make integration easier, we also built a simple API so the client can deploy and use the model in production with minimal setup.
Besides the model itself, we also delivered the code and documentation for training the model and guided their team through the entire process, so they could train the models and upgrade the code independently going forward.
 Python
Python
 PyTorch
PyTorch
 Numpy
Numpy
 Pandas
Pandas
 Matplotlib
Matplotlib
 Weights and Biases
Weights and Biases

The new version of text-based classification made category suggestions significantly more accurate, especially for long-tail categories. It replaced the existing model and gave KupujemProdajem a scalable system they could retrain and maintain themselves. Most importantly, it made posting easier for millions of users and gave the platform cleaner data to work with.



